Recently there have been some discussions on long file transfer times for certain new Automated Logic Optiflex controllers. These controllers are receiving a file that’s approximately 35MB in size but for some reason the transfer can take literal hours to complete if it is going over this VPN compared to minutes with a local network connection.
There is some speculation on the VPN tunnel I’ve implemented and if that’s making things worse. Admittedly the tunnel and hardware I’ve selected results in pretty poor bandwidth when you look at the numbers but here I’m going to expand why I did it that way and why I don’t think it matters.
The problem
In my original article I simply stated “The thing here is BACnet/IP and Modbus/IP are UDP protocols, and if you layer UDP on UDP over the internet things tend to go missing.” I never gave you any of my reasoning and research into this matter so let’s take a look at my findings from back in 2017.
My original test system had four sites in different geographic regions, different internet service providers plus a centrally located server in a test environment that acted as the OpenVPN server “hub”. The configuration of the OpenVPN tunnels was pretty much the recommended reference implementation from the OpenVPN “How To” article and of course had the recommended UDP tunnel. Under each of these sites there was a BACnet controller on it that had signal generator logic in it that was attached to a trend point and a BACnet analog value open to be read over the network. These programs also had analog network input points in them that would be linked to each of the other sites over the VPN network. These points would bind to the signal generator with a BACnet COV subscription. This way I am both recording the original signal generated in the module that made it and I have multiple other sites monitoring that point and recording the results over the network and the VPN tunnel.
These are some screenshots I pulled from that test system;
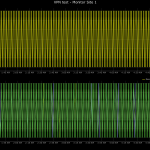
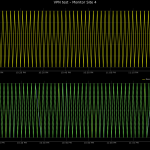
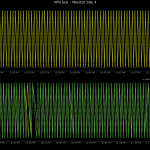
In each of these you can see the original point in yellow at the top of the trend graph. The bottom graph contains the results of each of the remote sites that were monitoring that point, these trends are layered on top of each other to make it easy to see breaks in the pattern. You can plainly see that somewhere somehow information is going missing between the sites. Why was that happening?
First of all let’s have a quick refresher on the difference between TCP and UDP transport layer differences;

I admit I stole that picture off of social media but it’s a great picture of what is going on. UDP sends packets of information to a receiver and if some go missing the UDP transport layer doesn’t do anything about it.
First let’s look at the simplified Open Systems Intercommunication model to understand the problem, I borrowed this picture from fiberbit.com;
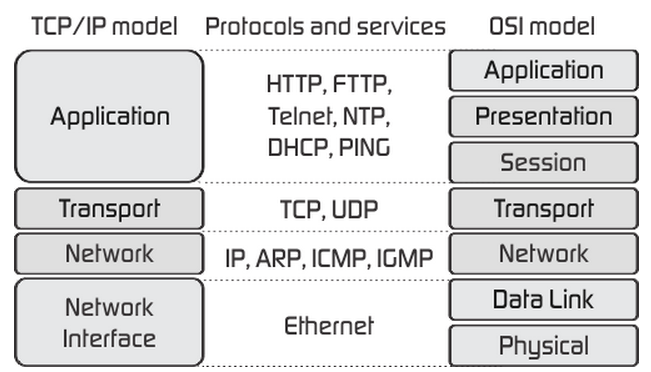
The traditional seven layer OSI model is on the right but there isn’t a whole lot I can so with those top three layers because they are all part of BACnet so it makes sense to deal with the simplified model on the left and in this case the application is BACnet/IP. I also can’t do anything with BACnet/IP being an unreliable UDP protocol on its transport layer.
Inside this BACnet application BACnet points can have a Change Of Value subscription or constantly poll for status. For a COV if a packet goes missing there will never be any corrective action taken, and only on many packets going missing for longer than the subscription timeout will anything be noticed by the receiving controller. For network traffic efficiency reasons COV is preferred but we can see it is especially vulnerable to missing packets.
In a constantly polled point when a packet goes missing we would generally have a timeout when nothing was received. We might know within seconds that this happened but if the next query was received the point would “return to normal” almost immediately. I wouldn’t set up alerts for such small outages.
Ideally the application layer would have checks and balances to make up for an unreliable transport layer but we can see that isn’t the case here for the occasional one or two packets missing. I believe that the engineers that designed the BACnet spec assumed that the transport layer would be reliable and not need these checks because in general hardwired Local Area Networks are very reliable. The problem is I am extending these LANs across the internet, multiple ISPs, and maybe even some wireless connections which might not be reliable.
What can I do?
While I can’t do anything about the BACnet/IP application or the UDP protocol it is built on I do control the VPN tunnel. In the reference implementation of OpenVPN for many good efficiency reasons the tunnel is UDP but this is going to be one of those special cases if we want BACnet data integrity.
OpenVPN packets encapsulate the data from one point to another, borrowing this picture from openmaniak.com;
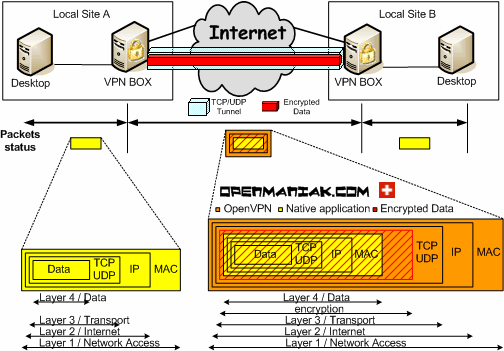
Changing the OpenVPN encapsulation packet to TCP takes advantage of the TCP three way handshake and can guarantee that the data gets to the other end unchanged and in the right order. Borrowing this image from intronetworks.cs.luc.edu diagramming the TCP three way handshake process;
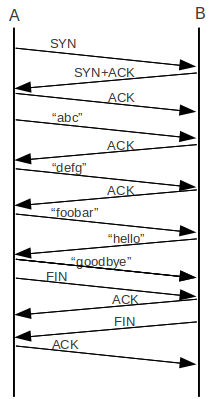
In short the TCP three way handshake is a series of queries and acknowledgements between the sender and receiver that will positively confirm the data transfer. If there is an interruption the message gets repeated which gives us some reliability through the VPN tunnel and over the “unreliable” public internet.
OK great, it’s reliable but isn’t it so slow it will impact performance?
It’s generally known that OpenVPN in general and the TCP implementation of OpenVPN in particular do not get great bandwidth numbers. Also, due to the crypto involved, these situations might require some significant CPU usage to get benchmarks where we want them and the choice of the Ubiquiti Edgerouter and it’s small CPU might play a role here. Let’s take a look at some test results.
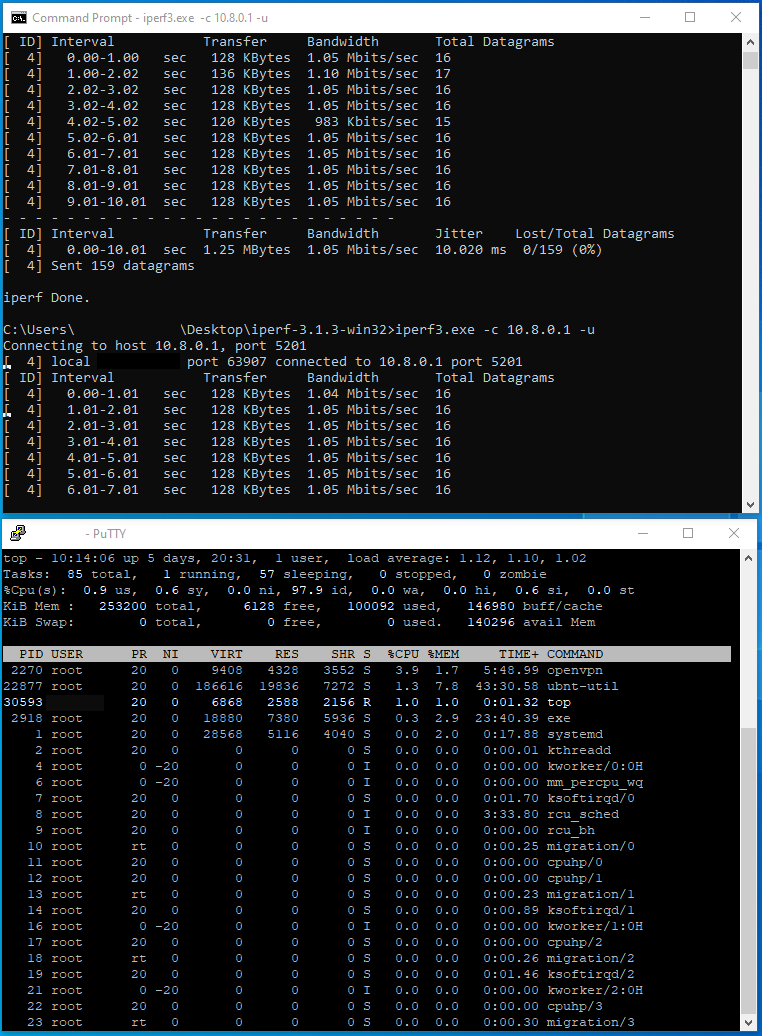
First off CPU usage at roughly ~4% tells me that we aren’t capped out on the Edgerouter X CPU. The other end of this particular tunnel has two cores of a Xeon E5-2650 v4 and OpenVPN usage doesn’t really register so I’m writing off CPU utilization as a cause here.
Next I’m looking at those bad iperf bandwidth results. I am testing with UDP traffic here and the packet size looks similar to what BACnet/IP uses but I’m only getting a little over 1Mbits/s. This is pretty bad when the datacenter ISP tests at 378.2Mbps download / 218.8Mbps upload with a Latency of 5 ms. The office ISP where this VPN client is tests at 93.1Mbps download / 86.9Mbps upload with a Latency of 7 ms. That’s bad bandwidth for office use for example but is that really a bad result in the BMS world? The actual file that we are moving across the network is only about ~35MB zipped, and the firmware folder which is what is being sent over the wire is still about ~35MB unpacked. So at ~1Mbits/s how long should it take to move a ~35MB file over this tunnel?
Using one of the calculators at https://techinternets.com/copy_calc?do
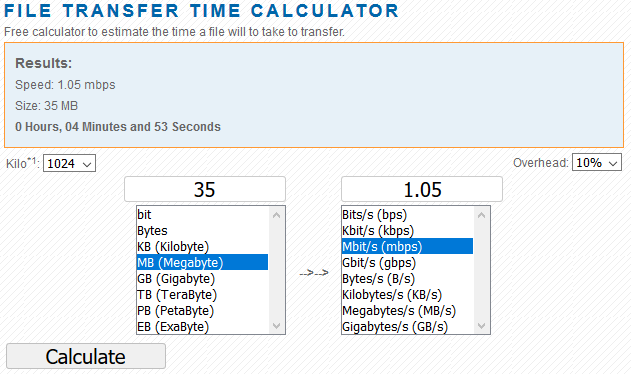
Here we can see even with 10% overhead it should take just under five minutes to move the files we need through the VPN tunnel. Even if I increase the overhead to 50% the time only goes up to six and a half minutes.
So what’s going on here?
If bandwidth isn’t the issue my next theory is latency. A direct LAN connection measures near 1ms of latency. So downloading straight from a laptop over a network cable results in quick download times like this;
Results G5RE on Ethernet drv_fwex_103-06-2045 -> drv_fwex_101-00-2056: 6:18 drv_fwex_101-00-2056 -> drv_fwex_103-06-2055: 6:26
That’s nice and quick and I will also mention the bandwidth here is gigabit. But over the VPN the times look more like this;
Server in Azure, OpenVPN connection to site and G5RE on Ethernet. drv_fwex_101-00-2056 -> drv_fwex_103-06-2055: 1:51:00 (almost 2 hours)
Latency in the tunnel doesn’t seem that bad to me even if I ping with a big packet;
C:\Users\me>ping 10.8.0.1 -t -l 4096 Pinging 10.8.0.1 with 4096 bytes of data: Reply from 10.8.0.1: bytes=4096 time=51ms TTL=127 Reply from 10.8.0.1: bytes=4096 time=52ms TTL=127 Reply from 10.8.0.1: bytes=4096 time=51ms TTL=127 Reply from 10.8.0.1: bytes=4096 time=51ms TTL=127 Reply from 10.8.0.1: bytes=4096 time=37ms TTL=127 Reply from 10.8.0.1: bytes=4096 time=53ms TTL=127 Reply from 10.8.0.1: bytes=4096 time=46ms TTL=127 Reply from 10.8.0.1: bytes=4096 time=52ms TTL=127 Reply from 10.8.0.1: bytes=4096 time=51ms TTL=127 Reply from 10.8.0.1: bytes=4096 time=51ms TTL=127 Reply from 10.8.0.1: bytes=4096 time=41ms TTL=127 Reply from 10.8.0.1: bytes=4096 time=27ms TTL=127 Reply from 10.8.0.1: bytes=4096 time=57ms TTL=127 Reply from 10.8.0.1: bytes=4096 time=41ms TTL=127 Reply from 10.8.0.1: bytes=4096 time=51ms TTL=127 Reply from 10.8.0.1: bytes=4096 time=52ms TTL=127 Reply from 10.8.0.1: bytes=4096 time=51ms TTL=127 Reply from 10.8.0.1: bytes=4096 time=52ms TTL=127 Reply from 10.8.0.1: bytes=4096 time=52ms TTL=127 Reply from 10.8.0.1: bytes=4096 time=52ms TTL=127 Ping statistics for 10.8.0.1: Packets: Sent = 20, Received = 20, Lost = 0 (0% loss), Approximate round trip times in milli-seconds: Minimum = 27ms, Maximum = 57ms, Average = 48ms
I discussed above where the time to download this file in the VPN tunnel using normal file transfer clients would be less than seven minutes worst case but there appears to be something unique about the way BACnet moves files that is sensitive to latency. We can see similar impacts in download times if I add BACnet routers into the mix.
Results G5RE on ARCnet under LGR drv_fwex_103-06-2055 -> drv_fwex_101-00-2056: 54:12 (almost one hour) drv_fwex_101-00-2056 -> drv_fwex_103-06-2055: 56.15
Here I’ve got a laptop connected straight to a BACnet router which should give us quick times but the download target is on the other side of the router on a ARCnet network segment. Add in the download speed calculator again and figuring for this ARCnet network bandwidth results in this calculated time;
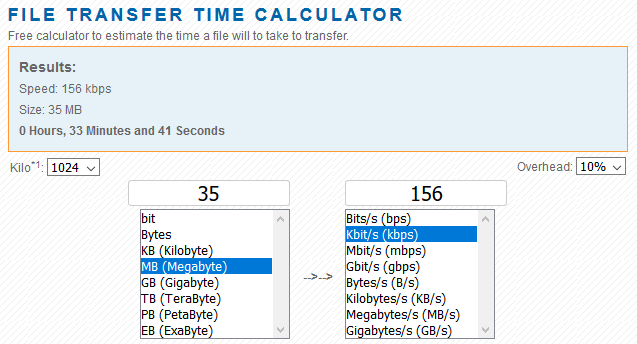
So calculated time is 35 minutes and real world took almost an hour. This is a token passing network but with only two nodes involved this isn’t too bad. What happens if I add in another ARCnet to ARCnet router? This results in quite a bit of latency as there are two token passing networks involved.
Results G5RE on ARCnet under AAR and LGR drv_fwex_103-06-2055 -> drv_fwex_101-00-2056: 3:02:25 (three hours...) drv_fwex_101-00-2056 -> drv_fwex_103-06-2055: Cancelled at 4:32:20, needed to go home. Was at 71% done.
Download times go through the roof, suddenly this 35MB file is taking three or more hours to get from A to B when the bandwidth calculations are suggesting it should take half an hour with the bandwidth available.
At this point I should get some wireshark data captures and start looking at latency in all three of these situations but I think I’m on to something with latency really upsetting the atomic file write transfer times in BACnet.